defalaw2linear(encode_data): """ G711 a律解码 :param encode_data: 经过编码的音频数据 :return: 解码后的音频数据 -> list """ # 用于储存解码结果 result = list() print("---G711 a-law decoding begins---") # 使用进度条方便查看处理进度 with alive_bar(len(encode_data), force_tty=True) as bar: for a_val in encode_data: # 将正负分离 a_val ^= 85 # 计算 t 的低 12 位 t = (a_val & QUANT_MASK) << 4 # 计算线性段索引 seg = (a_val & SEG_MASK) >> SEG_SHIFT
# 计算解码值 if seg == 0: t += 8 elif seg == 1: t += 264 else: t += 264 t <<= seg - 1 # 确定符号并将结果加入result if a_val & SIGN_BIT: result.append(t) else: result.append(-t) bar() return result
# 将整数数组转换为字节流 byte_stream = io.BytesIO() print("---Audio is being synthesized---") if sampwidth == 1: with alive_bar(len(data) * processbar, force_tty=True) as bar: for sample in chain.from_iterable(data): # 'B':无符号整数,将整数转换为一个长度为1字节的字符串 byte_stream.write(struct.pack('B', sample)) bar() elif sampwidth == 2: with alive_bar(len(data) * processbar, force_tty=True) as bar: for sample in chain.from_iterable(data): # 'h' 有符号短整型,将整数转换为一个长度为2字节的字符串 byte_stream.write(struct.pack('h', int(sample))) bar()
# 将字节流写入 with wave.open(output_path, 'wb') as wav_out: # 设置音频参数 wav_out.setnchannels(nchannels) wav_out.setsampwidth(sampwidth) wav_out.setframerate(framerate) wav_out.setnframes(nframes) # 按照参数将字节流写入 wav_out.writeframes(byte_stream.getvalue()) if sampwidth == 1: print('---G.711 A-law encoding is done---') elif sampwidth == 2: print("---G.711 A-law decoding is done---") print(f"The audio is saved in '{output_path}'") print("-" * 100)
# 超出预期线性段范围 if seg >= 8: result.append(127 ^ mask) else: # 计算编码值的高 3 位 aval = seg << SEG_SHIFT if seg < 2: aval |= (pcm_val >> 1) & QUANT_MASK else: aval |= (pcm_val >> seg) & QUANT_MASK # 计算完整 A-law 编码值并添加到result中 result.append(aval ^ mask) bar() return result
defalaw2linear(encode_data): """ G711 a律解码 :param encode_data: 经过编码的音频数据 :return: 解码后的音频数据 -> list """ # 用于储存解码结果 result = list() print("---G711 a-law decoding begins---") # 使用进度条方便查看处理进度 with alive_bar(len(encode_data), force_tty=True) as bar: for a_val in encode_data: # 将正负分离 a_val ^= 85 # 计算 t 的低 12 位 t = (a_val & QUANT_MASK) << 4 # 计算线性段索引 seg = (a_val & SEG_MASK) >> SEG_SHIFT
# 计算解码值 if seg == 0: t += 8 elif seg == 1: t += 264 else: t += 264 t <<= seg - 1 # 确定符号并将结果加入result if a_val & SIGN_BIT: result.append(t) else: result.append(-t) bar() return result
# 将元组转换为字节流 byte_stream = io.BytesIO() print("---Audio is being synthesized---") if sampwidth == 1: with alive_bar(len(data) * processbar, force_tty=True) as bar: for sample in chain.from_iterable(data): # 'B':无符号整数,将整数转换为一个长度为1字节的字符串 byte_stream.write(struct.pack('B', sample)) bar() elif sampwidth == 2: with alive_bar(len(data) * processbar, force_tty=True) as bar: for sample in chain.from_iterable(data): # 'h' 表示有符号短整型,将整数转换为一个长度为2字节的字符串 byte_stream.write(struct.pack('h', int(sample))) bar()
# 将字节流写入 with wave.open(output_path, 'wb') as wav_out: # 设置音频参数 wav_out.setnchannels(nchannels) wav_out.setsampwidth(sampwidth) wav_out.setframerate(framerate) wav_out.setnframes(nframes) # 按照参数将字节流写入 wav_out.writeframes(byte_stream.getvalue()) if sampwidth == 1: print('---G.711 A-law encoding is done---') elif sampwidth == 2: print("---G.711 A-law decoding is done---") print(f"The audio is saved in '{output_path}'") print("-" * 100)
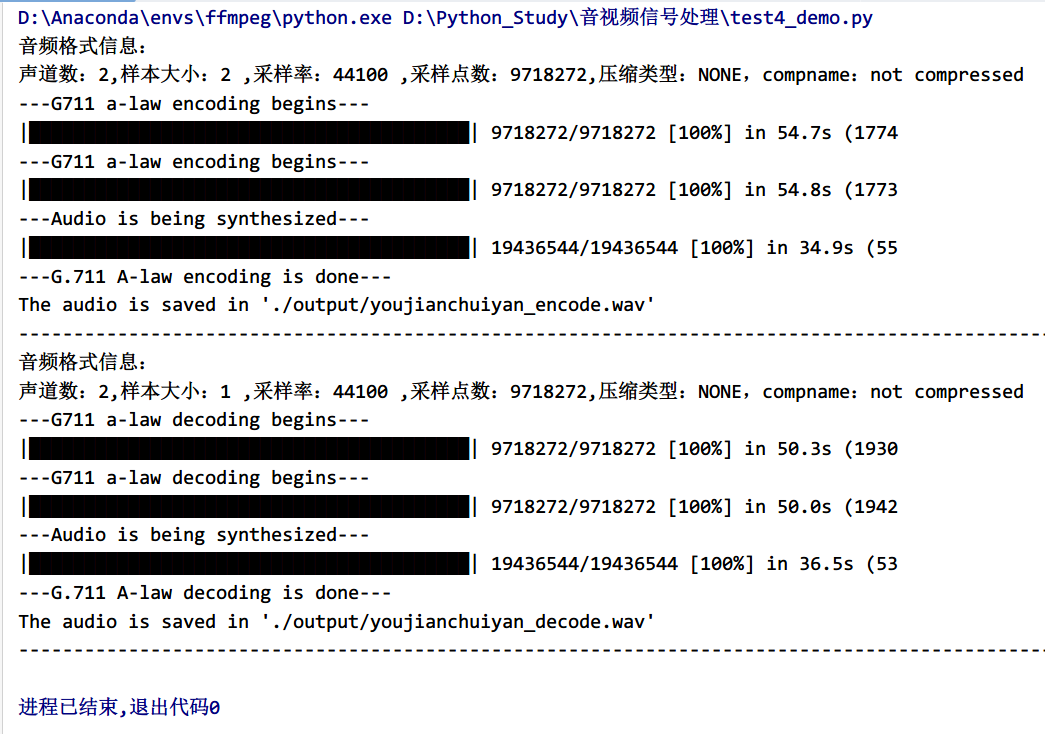
deftest_g711(audio_data, type=1): """ 对音频进行编码与解码操作 :param audio_data:待处理的音频数据 :param type:处理类型:1-编码 2-解码 :return:处理后的数据 -> list """ data = [] # 读取所有通道的音频信息 for channel in audio_data: # 编码操作 iftype == 1: encoded_channel = linear2alaw(channel) data.append(encoded_channel) # 解码操作 else: decoded_channel = alaw2linear(channel) data.append(decoded_channel) return data